King County House Prices: Regression Modeling
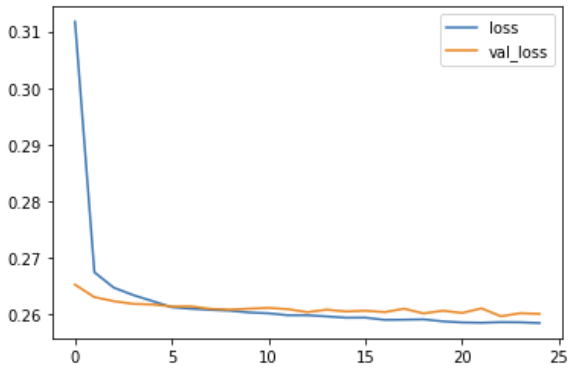
This project uses a dataset of over 21,000 residential sales in King County, WA, to build predictive models for house prices. Techniques applied include exploratory data analysis, multivariate linear regression, and tree-based ensemble models such as Random Forest and XGBoost.
Feature engineering was used to transform spatial coordinates, create interaction terms, and extract insights from dates and categorical fields. The final models were evaluated using RMSE and R² metrics, with SHAP plots used for interpretability.